第六章:数据持久化与数据库
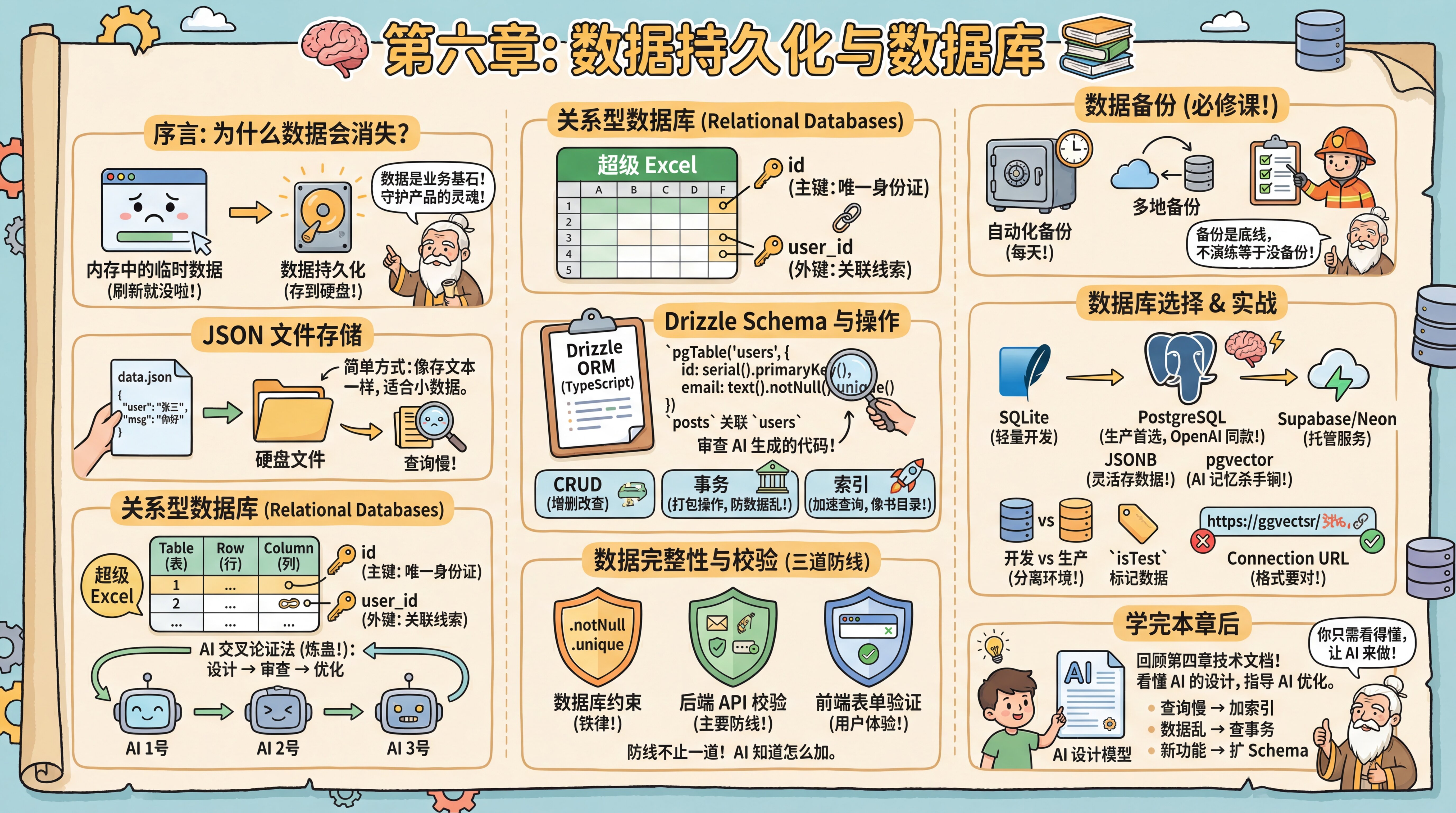
序言
界面搭建得有模有样了,但你发现一个尴尬的问题:每次刷新网页,刚才填写的表单、生成的对话全都不见了。
老师傅告诉你,这是因为浏览器里的数据默认只存储在临时的内存中。想要数据在关闭或刷新页面后依然存在,你需要数据持久化。
他严肃地提醒你:数据是所有业务的基石。前端代码丢了可以重写,UI 丑了可以换皮,但如果数据库里的用户数据丢了、乱了,你的产品就彻底完了。这就是为什么后端开发往往比前端更注重严谨性——因为你守护的是产品的灵魂。
JSON 文件存储
持久化不一定上来就要装复杂的软件。最简单的方式,其实就是把你之前在配置文件里学到的 JSON 格式利用起来,把数据存成 .json 文件。每一条聊天记录或用户信息,本质上就是一段文本。把它保存进硬盘的文件里,下次读取文件就能恢复。这种方式让你瞬间理解了“数据库”的本质——无非就是高效地读写硬盘上的文件。
关系型数据库
虽然 JSON 文件简单,但当你数据多了,想找"所有住在北京且年龄大于 20 岁的用户"时,就需要遍历整个文件,效率极低。于是你接触到了 Relational Databases(关系型数据库)。"关系"不是指人际关系,而是表和表之间通过共同字段连接起来——比如用户表和订单表靠 user_id 关联。老师傅让你把它想象成一个超级 Excel,理解它只需要掌握几个关键点:
- Table (表):就是一个 Excel Sheet(工作表),比如
Users表。 - Row (行):表里的一行,代表一条具体的数据(比如用户张三)。
- Column (列):表里的表头,定义了数据有哪些属性(姓名、年龄、邮箱)。
- Primary Key (主键):每一行数据的唯一身份证号(通常是
id),绝对不能重复。 - Foreign Key (外键):用来关联其他表的线索。比如在
Orders(订单)表中记录一个user_id,就能顺藤摸瓜找到这个订单属于哪个用户。
如何判断 AI 设计的表结构好坏? 新手往往很难一眼看出 Schema 设计得合不合理。老师傅传授了你一招**“AI 交叉论证法”**(俗称“炼蛊”):你让 AI 1号 帮你设计好表结构,然后把生成的代码发给 AI 2号 或 AI 3号 ,问它:“作为一个资深数据库架构师,根据我的PED和实际业务场景,这个设计是合理的设计吗,有什么潜在的性能隐患或逻辑漏洞?” 通常经过两轮这样的“左右互搏”,你就能得到一个非常健壮的数据库模型。
Drizzle Schema
操作数据库的标准语言是 SQL,在本教程中使用 Drizzle ORM。ORM 让你用熟悉的 TypeScript 代码操作数据库,不用手写 SQL。Drizzle 使用 TypeScript 定义 Schema(表结构定义——每张表有哪些列、什么类型),AI 会根据 PRD 文档自动生成。
比如 PRD 中写明"一个用户可以发布多篇文章",AI 会自动在 User 表添加 posts 字段,在 Post 表添加 authorId 外键。你的工作是审查 AI 生成的代码是否正确。
老师傅说:"数据库设计的关键是理解业务关系。AI 能处理技术实现,但'用户和订单是什么关系'需要你理解业务。"
为了能看懂 AI 交的作业,老师傅指着一段代码,逐行教你理解:
// src/db/schema.ts
import { pgTable, serial, text, timestamp, integer } from 'drizzle-orm/pg-core'
export const users = pgTable('users', {
id: serial('id').primaryKey(), // 自增主键
email: text('email').notNull().unique(), // 必填且唯一
name: text('name'), // 可选字段(不加 .notNull())
createdAt: timestamp('created_at').defaultNow(),
})
// 关联表示例
export const posts = pgTable('posts', {
id: serial('id').primaryKey(),
title: text('title').notNull(),
authorId: integer('author_id').references(() => users.id), // 外键关联
})pgTable:定义 PostgreSQL 表结构- 类型:
serial(自增整数)、text(文本,永远用 text 不要用 varchar)、boolean(布尔)、timestamptz(带时区时间)、integer(整数)、numeric(精确小数,金额必须用这个) - 可选字段:不加
.notNull()的字段默认可选 .unique():字段值唯一.references():定义表之间的外键关联
数据库操作
掌握数据库操作,你只需要理解三个核心概念。
CRUD 操作:虽然不用写 SQL,但你必须把 CRUD(Create 增、Read 查、Update 改、Delete 删)刻在脑子里。这是所有数据库操作的基石,也是你指挥 AI 操作数据的核心通用术语。
事务——保证数据完整性:老师傅补充了一个关键概念:"有些操作涉及多个数据库改动,必须'打包'执行。比如转账——从 A 账户扣钱、给 B 账户加钱。如果扣钱成功了但加钱失败,数据就乱了。" 事务(Transaction) 就是把多个操作打包成"要么全成功、要么全失败"的原子操作。这在处理金融、订单等关键业务时必不可少。
索引——加速查询:老师傅补充:"你可能会遇到一个问题——数据多了以后,查询越来越慢。比如在百万用户中查找某个 email,没有索引的话,数据库要一行行扫描。" 索引(Index) 就像书本的目录。没有索引,数据库要全表扫描;有了索引,直接定位到目标位置,速度快几十倍甚至上千倍。但索引不是越多越好。它占用额外空间,而且增删数据时要更新索引,反而影响写入性能。所以通常只在"经常查询的字段"上建索引,比如 email、created_at。特别注意:PostgreSQL 不会自动给外键列创建索引,这是最常见的性能陷阱,一定要手动加。
AI 知道什么时候需要使用事务、哪些字段需要建索引。你掌握这些核心概念,能更好地和 AI 沟通需求。
数据完整性与校验
"数据存进去了,"老师傅问,"但存得对不对?"
他给你举了几个例子:用户把邮箱填成了 hello(格式不对),年龄填成了 -5(范围不对),订单引用了一个不存在的用户 ID(引用完整性)。数据校验就是防止这种情况发生。
老师傅说,校验有三道防线:
第一道防线:数据库约束。在定义 Schema 时用的 .notNull()、.unique()、.references() 就是数据库层面的约束。这些是"铁律",就算代码有 bug,数据库也会拒绝违规数据。
第二道防线:后端 API 校验。在处理用户请求时,AI 会自动加上校验逻辑。比如邮箱格式、密码长度、枚举值范围等。这能在数据到达数据库前就拦截掉错误。
第三道防线:前端表单验证。用户提交前,浏览器先检查一遍。比如 <input type="email"> 会自动验证邮箱格式,HTML5 的 required、min、max 等属性也能做基本校验。
老师傅提醒你:三道防线各有用处。数据库约束是最后一道保险,后端校验是主要防线,前端校验是为了用户体验(快速反馈,不用等网络请求)。别因为有了前端校验就省略后端和数据库层面的保护——用户可以直接调用 API,绕过前端。
AI 知道在每一层应该加什么校验。你记住"防线不止一道"这个原则,和 AI 协作时就会更有方向。
数据备份
"在讲任何技术之前,"老师傅严肃地说,"先讲数据备份意识。数据是产品的灵魂,备份是开发的底线。很多人忽视了这一点,直到某天数据库崩溃,才发现所有用户数据都丢失了,这是灾难性的后果。
自动化备份不是可选项,而是必修课。备份策略要包括:自动备份(每天)、多地备份(云+本地)、定期恢复演练(验证备份可用)。太多人做了备份但从来没测试过,等到需要恢复时才发现备份文件损坏。
灾难恢复演练的重要性不亚于备份本身。如果没演练过,你根本不知道备份是否真的可用。"
数据库选择
为了实战,你接触到了 SQLite,它是一个轻量级的文件数据库,不需要安装,非常适合开发测试。但为了未来的扩展性,老师傅建议你使用 PostgreSQL。
PostgreSQL 的托管方式:Supabase 和 Neon 是两个流行的托管 PostgreSQL 云服务,但定位不同。
Supabase 是一个完整的 BaaS(Backend as a Service),除了 PostgreSQL 数据库,还提供 Auth 认证、Storage 存储、Realtime 实时订阅、Edge Functions 等功能。如果你想快速验证 MVP,不想操心后端细节,Supabase 是很好的选择。
Neon 则专注于数据库本身,提供无服务器架构的 PostgreSQL,可以按需自动扩缩容,适合对后端有自定义需求的场景。
但老师傅提醒你,本教程推荐使用标准的 PostgreSQL,而不是被任何 BaaS 捆绑。标准 PostgreSQL 让你更深入理解数据库的核心概念,迁移成本更低,未来可以根据需求选择任意托管平台或自建。Supabase、Neon、Railway 等都只是 PostgreSQL 的不同托管方式,你掌握的是数据库本身,而不是某个特定的服务平台。这种"不被捆绑"的思路,在 AI 时代尤为重要。
为什么是 PostgreSQL?举一个最有说服力的例子:OpenAI 的 ChatGPT 后端用的就是 PostgreSQL。他们用单一 PostgreSQL 主库支撑了 8 亿用户,每秒处理百万级查询。如果 PostgreSQL 能扛住 ChatGPT 的规模,那对你来说绝对够用了。
你可能好奇"主库"是什么。简单说一下主从库和高可用的概念:生产环境通常会有一个主库(负责写数据)和多个从库(负责读数据),主库的数据会自动同步到从库。这样既能分散读取压力,又能保证主库出故障时从库能顶上——这就是高可用的基本思路。不过这些是运维层面的事,开发阶段你只需要一个数据库就够用了,托管平台会帮你处理这些。
除了有顶尖 AI 公司背书,PostgreSQL 还有两个让 AI 开发者无法拒绝的特性:
- JSONB 支持:它虽然是关系型数据库,但能像 NoSQL(一类不要求固定表结构的数据库,存取更灵活但缺少关系约束)一样直接存 JSON 数据。这意味着你可以把 AI 生成的那些结构不确定的复杂数据直接丢进去,既有规则(SQL)又有灵活性(NoSQL)。
- pgvector(向量检索):这是 AI 时代的杀手锏。它可以存储和查询"向量数据"——向量是 AI 把文本转成的一串数字,用来衡量"两段话有多像"。这是实现 AI 长期记忆(RAG,Retrieval-Augmented Generation,让 AI 回答时能查阅你存进去的资料)的核心技术。选了 PostgreSQL,就等于为你的 AI 应用铺平了未来的路。
实战避坑
开发数据库 vs 生产数据库。老师傅告诉你,在专业团队里,通常会有两套数据库:开发环境用来测试和调试,生产环境给真实用户使用。虽然最佳实践是分离环境,但在学习阶段,用一套数据库快速上手是可以接受的——直接在云端数据库上开发,这样部署时不需要迁移数据,省去了很多麻烦。当你的应用有真实用户后,强烈建议分离开发和生产环境,以避免数据污染和安全风险。
数据标记:既然开发和生产共用一个数据库,怎么区分测试数据和真实数据呢?老师傅教了你两个办法:一是上线前手动清理测试数据;二是在表设计时加一个 isTest 或 isDev 字段,开发时写入的数据都标记为 true,上线后查询时过滤掉这些数据。这样既省钱又安全。
清理测试数据:当你需要删除测试数据时,告诉 AI "把所有测试数据删掉",它会生成类似 DELETE FROM users WHERE isTest = true 的代码。你看得懂这行代码的意思——只删除标记为测试的数据。这就是 isTest 字段的作用,它像一道安全闸门,确保只会删掉测试数据,不会误伤真实用户。
Connection URL(连接字符串) 你经常看到 Error: Invalid URL 的报错。老师傅告诉你,连接数据库就像寄信,格式必须严格遵守:postgresql://用户名:密码@主机地址:端口/数据库名。任何一个标点符号错了,或者密码里包含了特殊字符(需要转义),都会导致连接失败。
学完本章后
老师傅提醒你:学完本章后,建议回到第四章的技术文档,看看 AI 设计的数据模型。
现在你能看懂那些表结构、关联关系和索引了。如果 AI 的设计有问题,你能发现;如果没问题,你就放心用。掌握这些知识不是为了自己设计数据库,而是为了能看懂 AI 的设计,知道它在做什么。
什么时候需要调整:
- 查询变慢了 → 让 AI 加索引
- 数据不一致了 → 让 AI 检查事务
- 需要新功能了 → 让 AI 扩展 Schema
大部分时候,AI 的设计已经足够好。你只需要看得懂,知道怎么让 AI 优化就行。
小节导航
- 6.0 领取你的数据库 (./00-get-your-database.md)
注册 Neon/Supabase 免费套餐,创建数据库实例,获取连接字符串
- 6.1 数据存储演进 (./01-storage-evolution.md)
从 CSV 到 JSON 再到数据库的演进路径,本土化案例:豆瓣电影评分表
- 6.2 数据库基础概念 (./02-database-basics.md)
表、行、列、主键、外键、关联,本土化案例:美团外卖表关系
- 6.3 如何操作数据库 (./03-database-operations.md)
认识 Drizzle、Prisma 等 ORM,理解 AI 生成的 CRUD 代码
- 6.4 数据库设计与优化 (./04-database-design.md)
AI 交叉论证法、索引策略、行级安全(RLS)、连接管理、性能诊断下一章:第七章:后端API开发